请注意,这篇文章编写于2020年,其内容可能已经过时,请考虑使用性能更优的 Mug Diffusion 来生成音游谱面
前几天想玩玩 Malody ,但苦于找不到自己喜欢的曲子,于是脑子一抽,想到了万能的 AI。然后经过在网上的一阵搜索,我找到了一个大佬提出的解决方案。不过他只用了 24 首曲子训练了 2w 和 10w 步。为了尝试取得更好的效果,我扩大数据集到 104 首曲子,在 Kaggle 上训练了 20w 和 100w 步。效果嘛,经过我的测试,还是挺一般的(或者说根本不太好)。如果有想尝试的小伙伴照常前往橘子的实践时间瞧瞧。
效果展示
测试了 零和Zero-Sum、潮鳴り 和 R.I.P 三首曲子。在此感谢Ma娘献上的演奏~毕竟我真的是太菜了233
关于训练
训练过程中还是遇到了不少坑的,在此顺便记录吧。
准备和清洗数据
经过网上的一阵搜索,我找到了 Malody Mappack Project 作为原始数据。经过查看我发现里面有些 .osu 格式的转谱,显然这不是我们想要的东西。另外许多谱面有不同的难度,为了避免干扰,我们只选用 15-25 级的谱面,且越接近 20 级的谱面越优先,其余删除。另外其中一部分谱面带有 Key 音,我直接将其删除处理。为了清洗这些数据,我写了一段代码自动化处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import os
import sys
import json
import shutil
import random
os.mkdir("PreparedData")
for i in os.listdir(os.path.join(sys.path[0],"Data")):
path1 = os.path.join(sys.path[0], "Data", i)
if(not os.path.isdir(path1)):
continue
path2 = os.path.join(path1,os.listdir(path1)[0])
levelnumber = 0
levelfilepath = ""
for filename in os.listdir(path2):
filepath = os.path.join(path2,filename)
if(os.path.isfile(filepath)):
if(filename.endswith(".osu")):
print("删除:",path1)
shutil.rmtree(path1)
break
elif(filename.endswith(".mc")):
with open(filepath,"r",encoding="utf-8") as f:
mcfile = json.load(f)
version = mcfile["meta"]["version"]
level = version.split(" ")[-1]
if(level.strip().startswith("Lv.")):
levelint = int(level.strip().replace("Lv.",""))
if(levelint >= 15 and levelint <= 30 and (abs(20 - levelnumber) > abs(20 - levelint))):
levelnumber = levelint
levelfilepath = filepath
if(levelfilepath != ""):
dirpath = "PreparedData\\" + "%09d"%random.randint(0,999999999)
os.mkdir(dirpath)
shutil.move(levelfilepath,dirpath)
for file2 in os.listdir(path2):
filepath2 = os.path.join(path2,file2)
if(file2.endswith(".ogg") or file2.endswith(".mp3")):
shutil.move(filepath2,dirpath)
else:
os.remove(filepath2)
|
另外写了一小段程序自动打包成 .mcz 文件,mcz 其实就是一个zip文件。过于简单代码就不展示了。其实这个步骤可以简化,因为数据集生成的时候还是要解包的。但我实在懒得修改别人的代码。
生成数据集
数据集生成代码我就直接用了原作者的代码,丢到 Colab 上生成的。有几个 Bug,稍微修改了了一下。另外似乎有一个谱面咋整都报错,我懒得处理就直接将其删除了。其实这一步耗时令我意外的长,因为那几个 Bug 只有在某些谱面上出现,每次跳出来我都得重新生成一遍数据集,跑到会出错的文件,再看 Bug 的位置。如果要训练的话建议直接用我踩完坑修完 Bug 的版本。
训练模型
训练代码我进行了一定的修改,方便在运行的时候指定输出位置、备份位置、数据集位置和学习率、步数。另外还加入了写 TensorBoard 日志的支持。
刚开始我打算照常丢到 Colab 上训练,但 Colab 限制一个半小时无操作自动断开连接。由于训练步数多,耗时长,我寻思着总不能一直看着它吧。于是我决定把它放到 Kaggle 上训练。Kaggle 的笔记本最长运行9小时,且没有无操作超时的限制。
于是我就照 Colab 的样子在上面写了训练用的笔记本,就开始跑了。然后我遇到了本次项目最大的坑。
当我好不容易训练完之后,我在笔记本中到处寻找下载训练的模型的地方。我好不容易在Data那一栏找到了下载按钮,按一按,莫得反应。我大惊,尝试挂载 Google 云端硬盘,发现 Kaggle 并不能像 Colab 一样轻松挂载 GoogleDrive。我尝试退出重新进入笔记本,然后我训练出来的文件就都无了。
后来我查了半天,才知道 Kaggle 训练是写好代码之后点右上 SaveVersion,然后 Save&Run All,训练完之后再去取结果,而不是像 Colab 一样交互式使用。等过一阵子我打算再写一篇 Kaggle 的使用教程。
以下是 Kaggle 笔记本代码。需要加载我的数据集。
1
2
3
4
| !git clone https://github.com/mirrorange/AI_beatmap_generator.git
%cd AI_beatmap_generator
!cp /kaggle/input/malody4kbeatmaps/malody.txt glove
!cp /kaggle/input/malody4kbeatmaps/malody2.txt glove
|
1
2
3
4
5
| %cd glove
!make
!./create_glove_embedding.sh
!./create_ln_embedding.sh
%cd ..
|
1
2
3
4
5
6
7
8
| !rm -rf checkpoints
!mkdir checkpoints
!mkdir log
!mkdir /kaggle/working/checkpoints
!python train_beat_cls.py /kaggle/working/AI_beatmap_generator/checkpoints /kaggle/working/checkpoints /kaggle/input/malody4kbeatmaps/dataset.json 0.0002 200
!python train_beat_decoder.py /kaggle/working/AI_beatmap_generator/checkpoints /kaggle/working/checkpoints /kaggle/input/malody4kbeatmaps/dataset.json 0.0002 1000
!python train_ln_cls.py /kaggle/working/AI_beatmap_generator/checkpoints /kaggle/working/checkpoints /kaggle/input/malody4kbeatmaps/dataset.json 0.0002 200
!python train_ln_decoder.py /kaggle/working/AI_beatmap_generator/checkpoints /kaggle/working/checkpoints /kaggle/input/malody4kbeatmaps/dataset.json 0.0002 1000
|
最后是训练日志
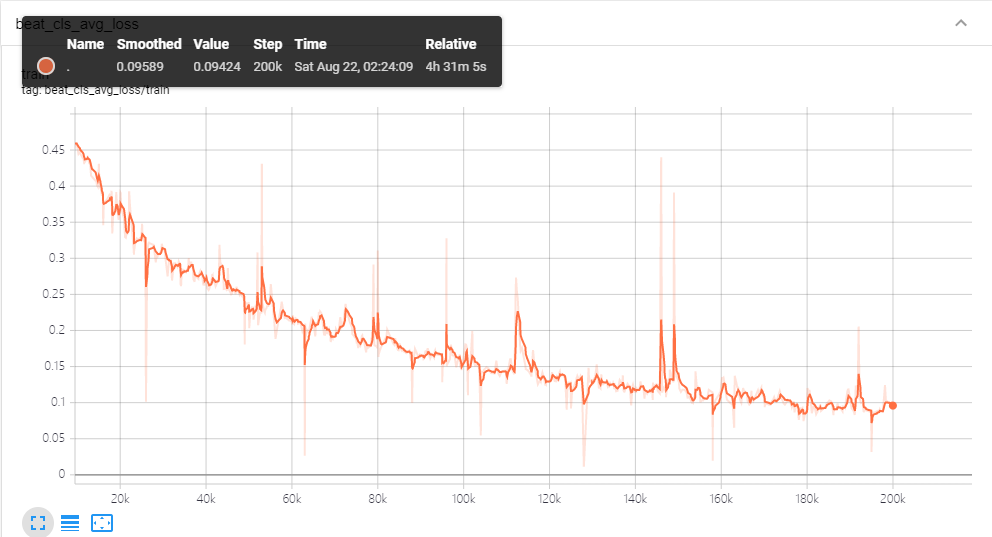
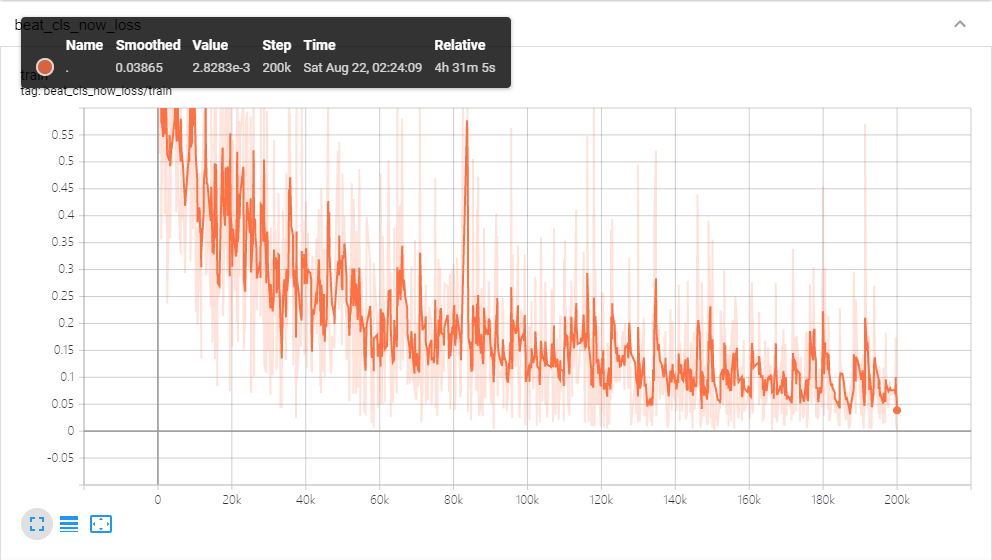
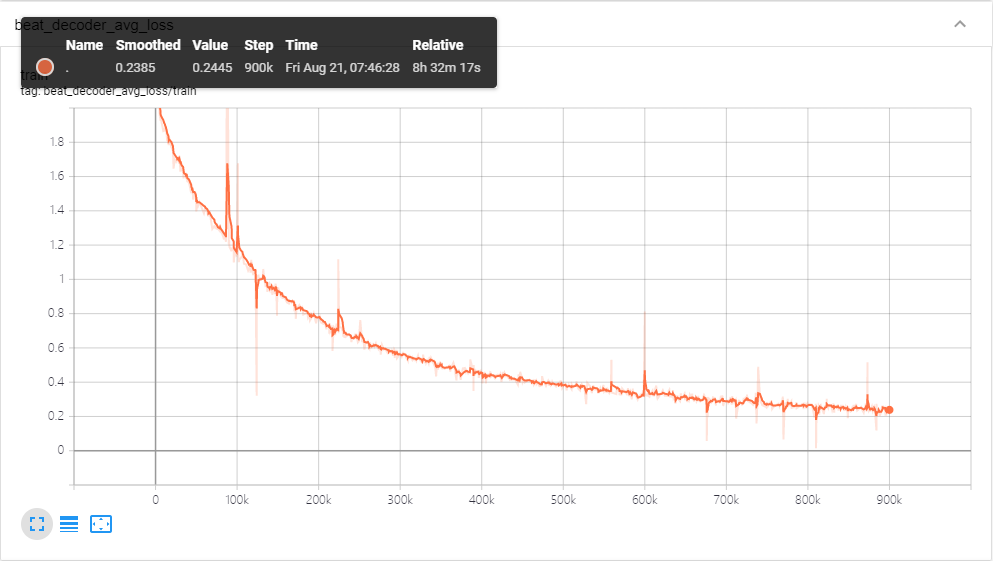
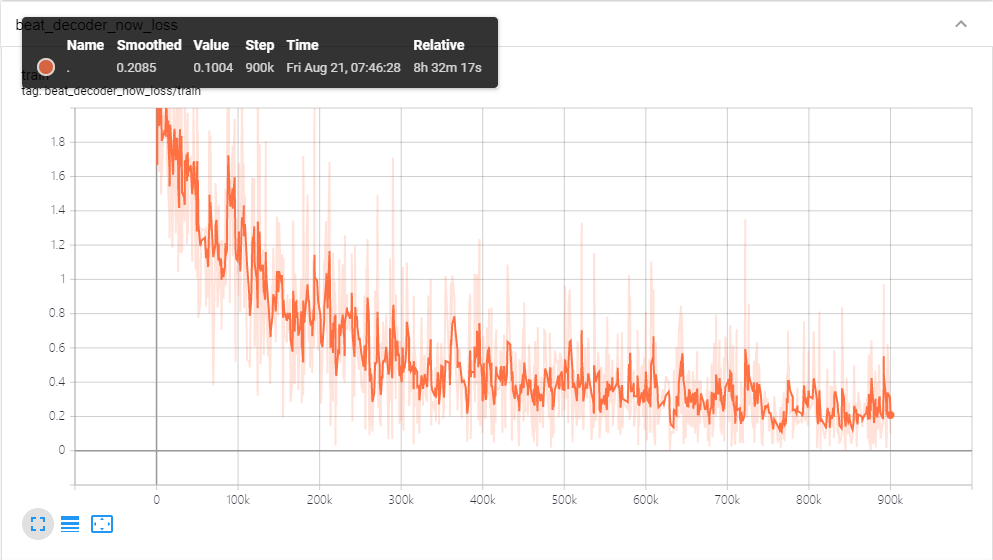
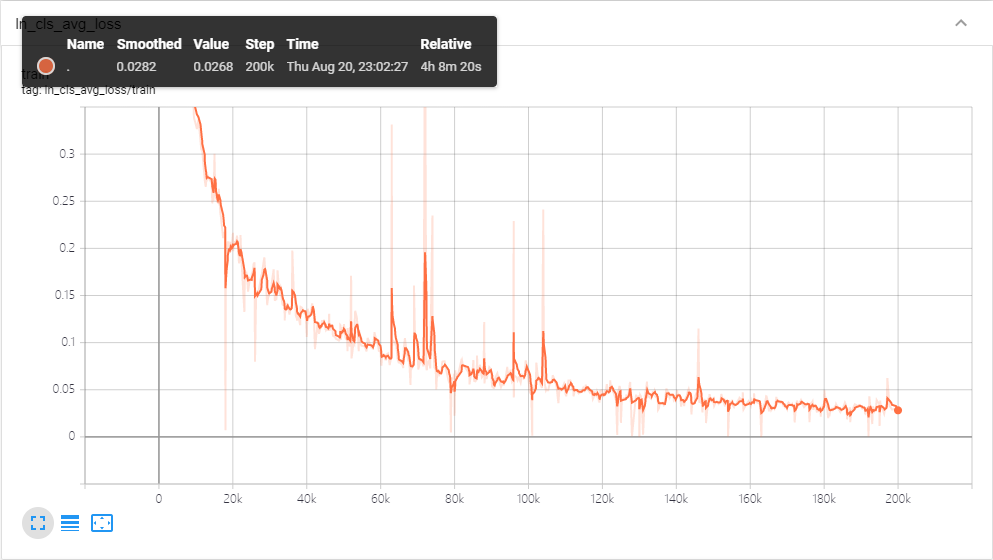
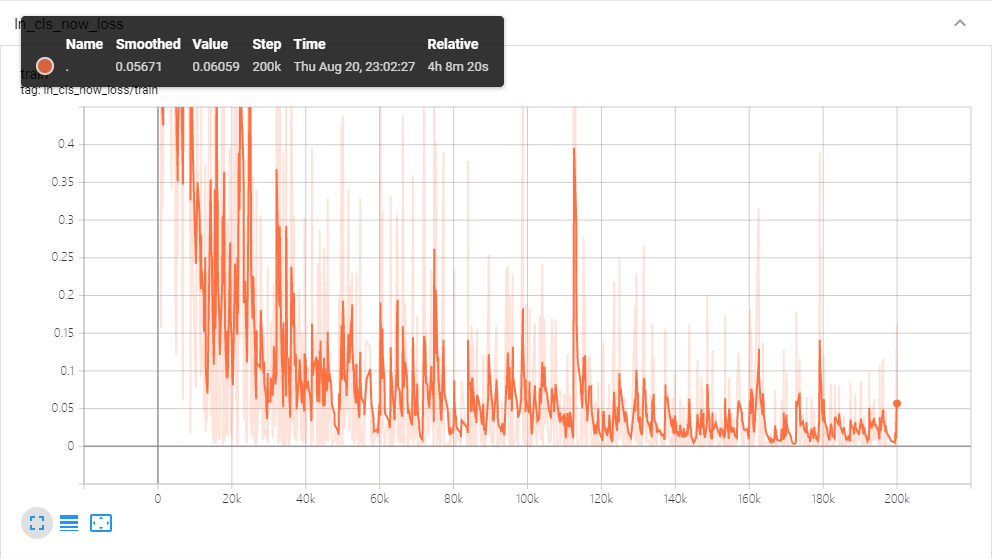
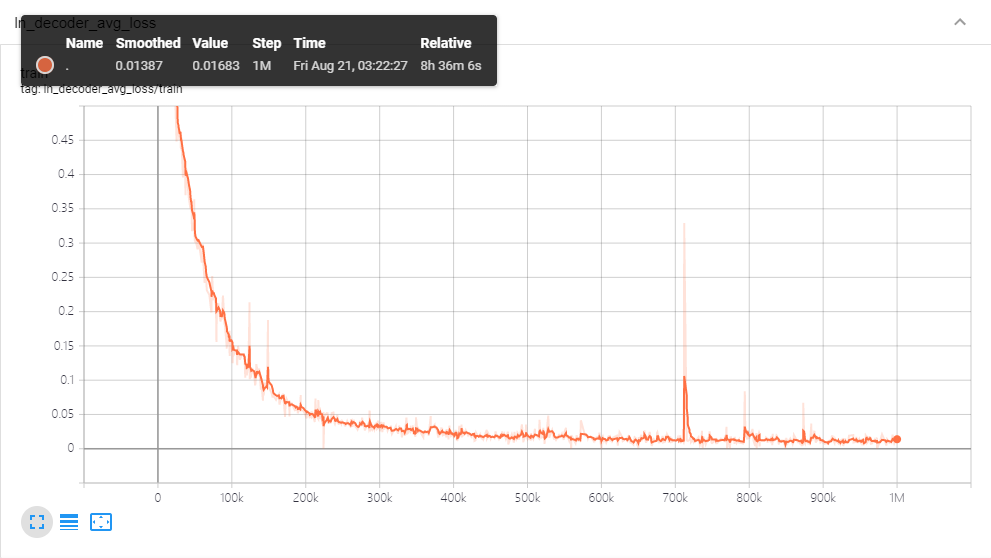
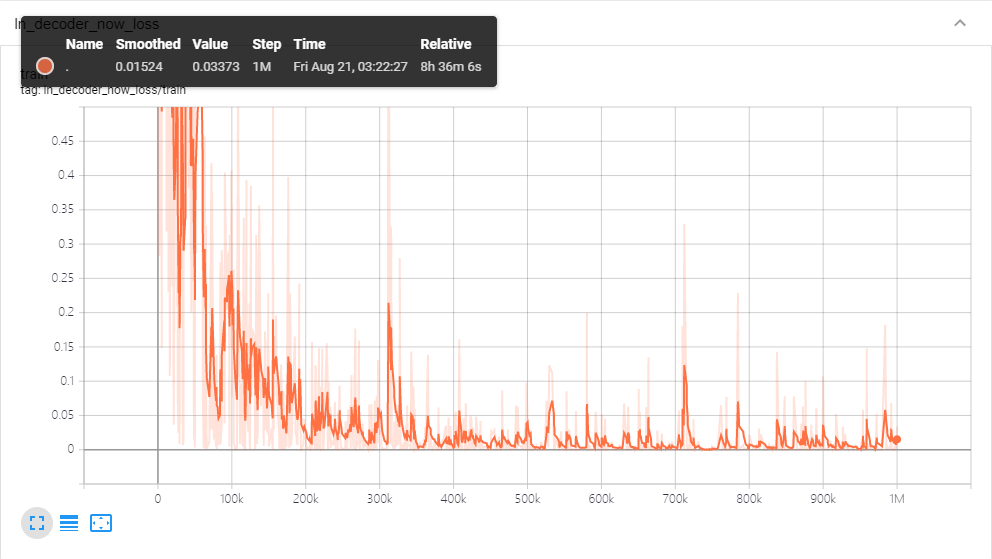
附各种数据的获取地址
AI Beatmap Generator(源仓库)+ 原模型
AI Beatmap Generator(橘子修改版)+ 橘子训练的模型
Malody Mappack Project 项目页面
橘子清洗过的数据(104张谱面)及预处理过的数据集
橘子为训练编写的Kaggle笔记本
生成的示例谱面:潮鳴り、零和Zero-Sum、R.I.P.